MP10 note
感觉算是一个很有难度的MP,也可能是我之前没怎么用过动态内存分配,导致调试的时候一直运行时错误。
后来用了Valgrind辅助调试(不然内存的错误真的很难找)。
所以,还是很有记一记的必要。也帮助大家解决这个MP,和提供一种调试的思路。
MP10简介
MP10其实是MP9的一个升级版,主要功能还是通过 pyramid tree 查找平面中的点集,然后通过堆优化的dijkstra算法找出src和dst两个点集之间的最短路。
但是与MP9相比,MP10有以下几个改动:
- 实现了动态内存分配
- minimap优化
- 实现了将多个request进行匹配(称MP9中找到两个request中共用的最短路的过程为“匹配”)
接下来,分别记录这三个方面。
动态内存分配
首先要完成 mp10alloc.c 文件中的三个函数:
1 | vertex_set_t* new_vertex_set () |
用 malloc() 实现内存分配,需要注意的是,区分 vertex_set_t 结构体中的 count 和 id_array_size 两个变量。count 是指点的个数,id_array_size 则是指 id 这个数组的大小。
在后面增加数组长度的时候,我采用的方法是每次数组长度 $\times 2$,就是把 id_array_size $\times 2$ 之后 realloc。
new_vertex_set中把minimap变量也初始化free过后的指针设为NULL,防止再次访问
在 mp9.c 的 find_node 函数中也要做出相应的变化,主要是加入一个点,判断 count 和 id_array_size 的关系,如果数组大小不够了,就要 realloc。
1 | if (4*nnum+1 > p->n_nodes) { |
dijkstra 中的路径也需要先算出路径长度,然后分配内存,再将最短路写进去。比较简单,这里就略过了。
minimap 优化
如果一个平面上有很多很多点,是否有一种方法能快速判断两个点集有没有交集?如果能快速判断两个点集没有交集,就省去了不必要的合并,那就可以提高匹配request的效率。
我们回想一下 pyramid tree 这个数据结构:
pyramid tree 的0号结点(根节点)对应一整个平面,然后根节点的4四个后代(1,2,3,4)将平面分为了四个部分,分别是:
- $1: (p,q)|p<x,q<y_{left}$
- $2: (p,q)|p>x,q<y_{right}$
- $3: (p,q)|p<x,q>y_{left}$
- $4: (p,q)|p>x,q>y_{right}$
第一层 pyramid tree $1$ 个结点,将平面分为 1 块区域
第二层 pyramid tree $4$ 个结点,将平面分为 4 块区域
第三层 pyramid tree $8$ 个结点,将平面分为 8 块区域
以此类推。
我们考虑第五层的 pyramid tree,将平面分为64个区域,我们将这64个区域中的每个区域对应 uint64_t 无符号整数的一位(bit)。然后我们考虑一个点集中的 minimap 的含义就是:如果 minimap 的第 i 位是 1, 那么这个点集中在平面中的区域 i 有点。
那么如果将两个点集的 minimap 进行按位与运算,如果 minimap1 & minimap2 == 0 那么显然,这两个点集没有交集。
首先我们完成 int32_t mark_vertex_minimap (graph_t* g, pyr_tree_t* p) 函数,来找到每个点属于哪个区域,也就是找到每个 pyramid tree 的叶子节点的在第五层的祖先结点编号,然后 $-21$ 得到的值。
1 | for (int32_t i = 0; i < p->n_nodes; ++i) { |
然后完成 void build_vertex_set_minimap 函数,也就是合并点集每个结点的 mm_bit 到 minimap 变量,注意在此之前要将 minimap 变量初始化为0。
多request匹配
首先,我们有两个request类型的链表,available 和 shared。available 存还没有匹配上的request,shared 存已经匹配的request。对于shared链表中的每个元素,不仅有next指针,还有partner指针,指向与之配对的request。
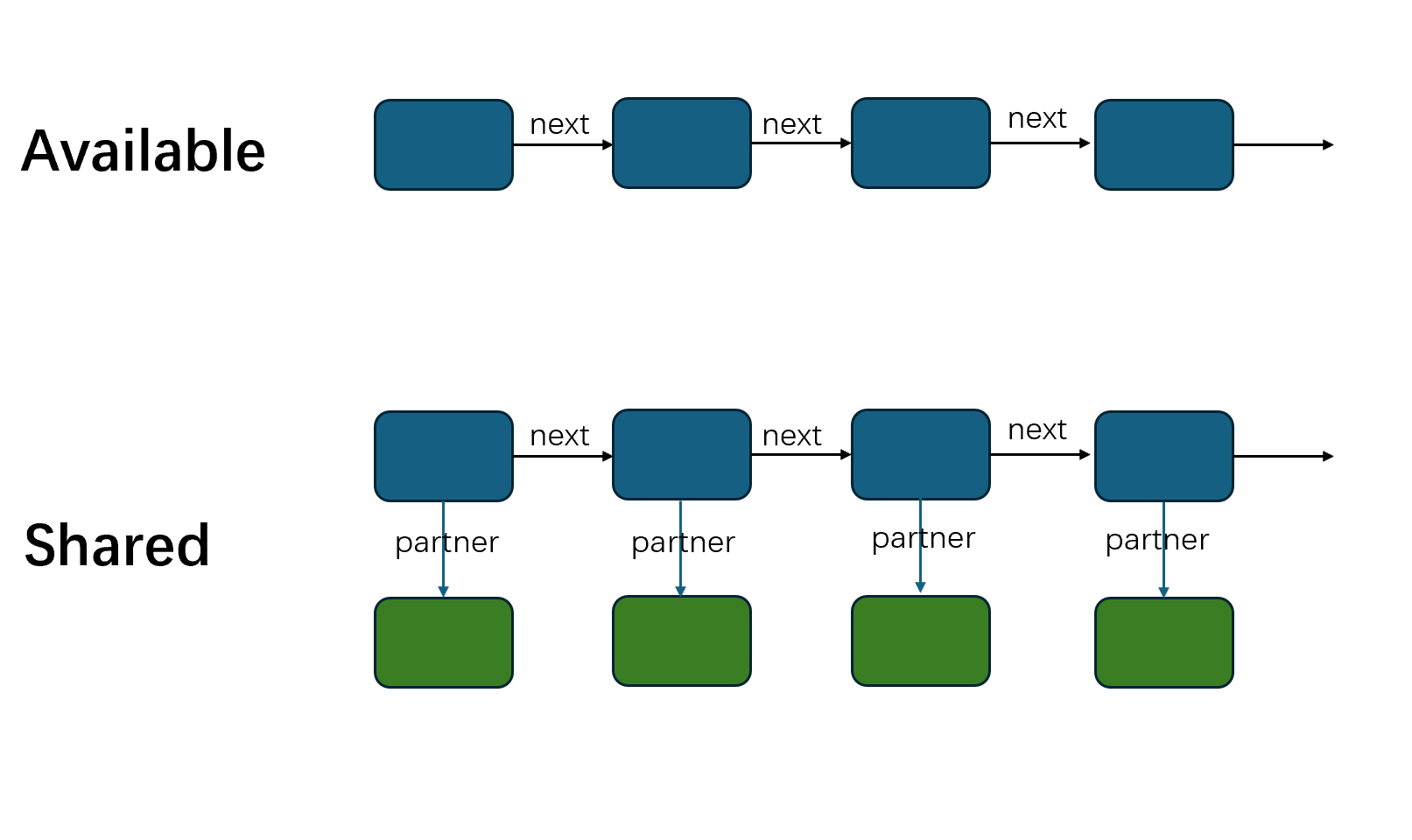
我们会有很多个request,对于每个新来的request,我们需要遍历available链表,查看是否能够匹配。假设在available中找到了 cur 与新的request r 相匹配,则将 cur 从 available链表中删除,将 r 插入 shared 链表。
配对的时候,先用 minimap 判断有没有交集,如果没有就可以skip。
调试心得
一开始遇到最多的问题就是
1 | realloc(): invalid old size |
以及
1 | double free or corruption (out) |
也卡了很长时间。
一开始一直以为是自己的 realloc 和 free 函数用错了,结果后来发现是数组越界。所以C语言在运行时的错误信息,编译器的反馈不一定准确。
后来使用了 valgrind (一款用于内存调试、内存泄漏检测的软件开发工具)辅助调试才把bug修复。个人感觉valgrind的报错信息一般情况下都还是准确的,所以下面介绍一下valgrind的安装及使用。
在 Linux 可以使用下面的命令安装 valgrind:
1 | $ wget ftp://sourceware.org/pub/valgrind/valgrind-3.23.0.tar.bz2 |
编译程序时,需要加上-g选项(我们的make文件中已经加了)
使用 valgrind 检测内存使用情况:
1 | $ valgrind --tool=memcheck --leak-check=full ./mp10 graph requests |
下面记录了几个我用 valgrind 查出的bug(由于bug已经被修复了,只能只能凭印象描述一下bug QAQ)
变量没有初始化
valgrind反馈
1 | ==332053== Conditional jump or move depends on uninitialised value(s) |
也就是说,在 mp10match.c 文件的第 85 行,具体位置是 handle_request 函数内部。Valgrind 指出,程序在这里进行了一个条件跳转或者数据移动操作,但是它依赖于未初始化的值,导致了错误。
bug
在 build_vertex_set_minimap 函数中,minimap 没有初始化为0。
数组越界
valgrind反馈
1 | ==338005== Invalid read of size 4 |
这个错误发生在 mp9.c 文件的 find_nodes 函数的第 17 行,并且 Valgrind 指出这是一个 “Invalid read of size 4” 错误。同时,Valgrind 给出了更详细的信息:错误发生在 find_nodes 函数内部,但多次在不同的位置调用了该函数。
bug
- 在
find_node函数中,插入元素时数组越界 find_node递归的时候,判断边界情况时多加了=
访问无效指针
valgrind反馈
1 | ==355941== Invalid read of size 8 |
根据 Valgrind 的输出,出现了 “Invalid read of size 8” 错误,表明在程序中发生了对大小为 8 字节的内存块的无效读取。这种错误通常与指针的错误使用相关。
具体来说,错误发生在 mp10match.c 文件的 free_all_data 函数的第 218 行。Valgrind 指出,这是一个对已经释放的内存块进行读取的错误,而且读取的位置在这个内存块的 64 字节内。
bug
在找到匹配的request时,没有将这个request的 next 指针设为 NULL
乐子
如何评价这是作者的MP10?